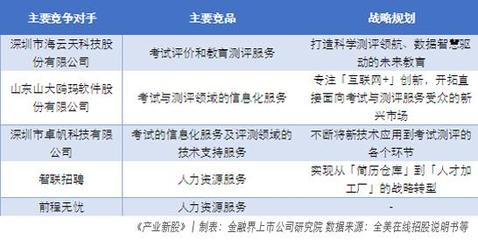
在深圳這座以創(chuàng)新和速度著稱的城市,一家名為“金騰科技”的互聯(lián)網(wǎng)信息服務企業(yè)正悄然成為行業(yè)關注的焦點。憑借其背后兩大重量級股東——中國國際金融股份有限公司(中金)和騰訊控股的強力支持,金騰科技正以融合了金融智慧與科技基因的獨特姿態(tài),在競爭激烈的市場中加速發(fā)展。
一、 強強聯(lián)合的資本與生態(tài)背書
金騰科技的誕生與發(fā)展,自始至終都帶有鮮明的“強強聯(lián)合”色彩。
- 中金的深度賦能:作為中國頂尖的投資銀行和金融機構,中金的入局不僅為金騰科技帶來了雄厚的資本支持,更重要的是注入了深厚的金融行業(yè)理解、嚴謹?shù)娘L險管理理念以及廣泛的金融網(wǎng)絡資源。這使得金騰科技在探索金融科技服務、企業(yè)級解決方案時,具備了更高的起點和更穩(wěn)健的底層邏輯。
- 騰訊的生態(tài)加持:騰訊的加入,則為金騰科技插上了“互聯(lián)網(wǎng)+”的翅膀。騰訊在云計算、大數(shù)據(jù)、人工智能、社交網(wǎng)絡及產(chǎn)業(yè)互聯(lián)網(wǎng)領域的深厚積累與龐大生態(tài),為金騰科技提供了強大的技術底座和豐富的應用場景。這種結合,使得金騰科技能夠更高效地開發(fā)面向企業(yè)和個人用戶的創(chuàng)新型互聯(lián)網(wǎng)信息服務產(chǎn)品。
這種“金融+科技”的股東背景組合,在國內企業(yè)中并不多見,它讓金騰科技在戰(zhàn)略布局上能夠兼顧合規(guī)穩(wěn)健與技術前瞻,具備了解決復雜商業(yè)問題的獨特能力。
二、 定位與核心業(yè)務聚焦
深圳金騰科技的核心業(yè)務聚焦于“互聯(lián)網(wǎng)信息服務”,這并非一個寬泛的概念,而是在兩大股東優(yōu)勢交集下的精準定位。其業(yè)務方向可能重點圍繞以下幾個層面展開:
- 金融科技解決方案:利用中金的金融專業(yè)能力和騰訊的技術能力,為金融機構提供數(shù)字化轉型所需的IT解決方案、數(shù)據(jù)分析工具、智能風控模型以及精準營銷平臺等服務。
- 產(chǎn)業(yè)互聯(lián)網(wǎng)服務:依托騰訊的B端生態(tài)和技術,結合中金對產(chǎn)業(yè)鏈的深刻理解,為實體企業(yè)(尤其是與金融關聯(lián)密切的行業(yè))提供供應鏈管理、數(shù)字營銷、企業(yè)運營效率提升等綜合信息服務。
- 創(chuàng)新型數(shù)字內容與平臺服務:在合規(guī)框架下,探索將金融信息服務與騰訊的社交、內容生態(tài)相結合的可能性,面向更廣泛的用戶群體提供有價值的信息產(chǎn)品和平臺體驗。
其發(fā)展路徑,很可能是以To B(企業(yè)服務)作為切入點和基石,在特定垂直領域建立優(yōu)勢后,再向更廣泛的場景延伸。
三、 深圳土壤與加速發(fā)展動因
選擇深圳作為大本營,為金騰科技的加速發(fā)展提供了得天獨厚的條件:
- 政策與創(chuàng)新環(huán)境:深圳是中國乃至全球的科技創(chuàng)新中心,擁有最友好的創(chuàng)新政策、最活躍的資本市場和最密集的高科技企業(yè)集群,這為金騰科技吸引人才、尋找合作伙伴、快速試錯迭代提供了絕佳環(huán)境。
- 人才集聚效應:深圳匯聚了來自全國的科技、金融精英,金騰科技可以便捷地吸引到既懂金融又懂科技的復合型人才,這是其業(yè)務發(fā)展的核心引擎。
- 市場前沿陣地:深圳及粵港澳大灣區(qū)企業(yè)數(shù)字化轉型需求旺盛,金融市場活躍,是驗證和推廣金融科技及產(chǎn)業(yè)互聯(lián)網(wǎng)服務的理想試驗田和首發(fā)市場。
四、 未來展望與行業(yè)影響
背靠中金與騰訊,坐擁深圳地利,金騰科技的加速發(fā)展預示著一種新的產(chǎn)業(yè)融合模式正在成熟。它不再僅僅是單純的“金融科技”公司或“互聯(lián)網(wǎng)”公司,而有望成為連接金融資本、實體產(chǎn)業(yè)與數(shù)字技術的新型樞紐。
其未來的挑戰(zhàn)在于如何高效整合兩大股東的資源,形成獨特的、可持續(xù)的核心競爭力,并在具體的產(chǎn)品和服務上實現(xiàn)突破,真正創(chuàng)造出市場認可的價值。如果成功,金騰科技不僅將成為股東生態(tài)協(xié)同共贏的典范案例,更有可能成長為深圳乃至全國互聯(lián)網(wǎng)信息服務領域,特別是在產(chǎn)融結合深度服務方面的又一重要力量。
深圳金騰科技的故事,是資本、技術、區(qū)位與時代機遇共同書寫的故事。它的加速發(fā)展,正為我們觀察中國數(shù)字經(jīng)濟下半場——即互聯(lián)網(wǎng)技術與實體經(jīng)濟、金融資本深度融合——提供一個極具價值的樣本。