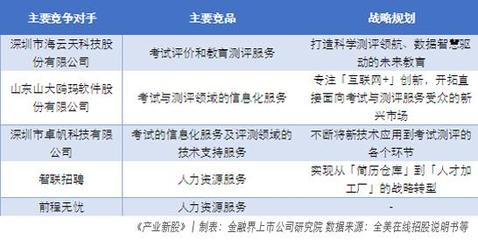
在全球化與數字化浪潮交織的時代,深化國際合作、拓展服務渠道已成為推動科技發展與產業升級的關鍵路徑。我院始終秉持開放協作的理念,近期與韓國電子通信研究院(ETRI)等多家國際知名科研院所及領先企業開展了一系列富有成效的合作交流,旨在共同探索深圳互聯網信息服務領域的創新機遇,構建互利共贏的發展新格局。
此次合作交流的啟動,標志著我院在國際化產學研融合道路上邁出了堅實一步。韓國電子通信研究院作為全球信息通信技術領域的頂尖研究機構,其在5G/6G通信、人工智能、物聯網等前沿領域擁有深厚的技術積淀和豐富的產業化經驗。通過高層互訪、技術研討會、聯合項目洽談等多種形式,雙方就互聯網信息服務的基礎設施建設、數據安全與隱私保護、智慧城市應用、下一代網絡技術等共同關心的議題進行了深入探討。我們不僅學習了對方在技術研發與標準制定方面的先進經驗,也向合作伙伴充分展示了深圳在互聯網產業生態、市場活力以及應用創新方面的獨特優勢。
合作的核心目標之一是共同拓展服務渠道。我們認識到,單一的研發或服務模式已難以應對日益復雜的市場需求與技術挑戰。通過與ETRI等機構建立戰略伙伴關系,我們得以整合雙方的研發資源、市場網絡與專業知識,共同設計并推出更貼合區域及全球市場需求的技術解決方案與服務產品。例如,在面向企業的云服務優化、面向市民的數字化公共服務平臺、以及支撐數字經濟的新型信息基礎設施等領域,雙方正在探討聯合研發與試點落地的可能性,旨在將前沿技術轉化為可規模化、高效能的服務能力。
促進合作共贏,是貫穿所有交流活動的主線。共贏不僅體現在商業利益的共享上,更體現在知識創造、人才培養與行業標準的共同推進上。我們計劃建立常態化的學者與工程師互訪機制,聯合培養高水平的科研與技術人才;推動建立聯合實驗室或創新中心,聚焦特定關鍵技術進行攻關;并積極參與乃至共同發起國際性的技術標準與行業規范討論,力爭在未來的互聯網信息服務藍圖中嵌入更多來自中國深圳的創新元素與合作成果。
深圳,作為中國改革開放的前沿陣地和全球知名的科技創新中心,其互聯網信息服務產業規模龐大、生態健全、創新活躍。我院與韓國電子通信研究院等國際伙伴的合作,正是扎根于這片熱土,放眼于全球市場。我們相信,通過持續深化這種高水平的國際科技合作,不僅能夠加速我院自身研究能力的提升和服務體系的完善,更能為深圳乃至粵港澳大灣區的互聯網信息服務產業注入新的動能,共同應對挑戰,分享發展機遇,最終為實現數字時代的包容性增長與可持續繁榮作出貢獻。
我院將繼續以開放的心態,拓展與全球更多優秀機構的合作網絡,不斷豐富合作內涵與形式,將‘拓展服務渠道,促進合作共贏’的理念落到實處,攜手伙伴共同繪制互聯網信息服務創新發展的新篇章。