隨著科技的飛速發展,工廠自動化生產設備已成為現代制造業的核心驅動力。機械科技在這一領域的應用,不僅提升了生產效率,還顯著降低了人工成本,推動了工業智能化的進程。
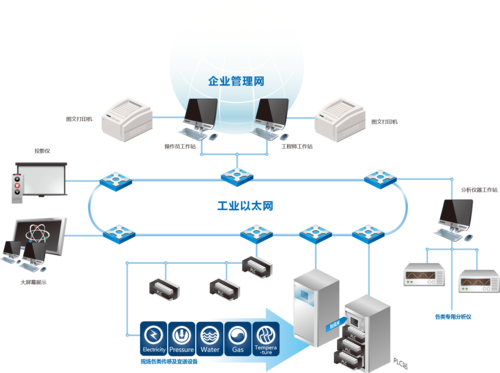
自動化生產設備的核心在于其高度集成的機械系統。例如,工業機器人通過精密的伺服電機和傳感器,能夠執行復雜的裝配、焊接和搬運任務,確保生產過程的精確性和一致性。這些設備通常采用可編程邏輯控制器(PLC)和計算機數控(CNC)技術,實現全自動化的流水線操作。在汽車制造、電子組裝和食品加工等行業,自動化設備已廣泛應用,大幅縮短了產品周期,并減少了人為錯誤。
機械科技的進步還體現在智能監控與維護上。通過物聯網(IoT)和人工智能(AI)技術,自動化設備可以實時收集數據,預測潛在故障,并自動調整參數以優化性能。例如,智能傳感器能監測設備振動、溫度和磨損情況,提前發出警報,避免生產中斷。這不僅提高了設備的可靠性,還延長了其使用壽命。
自動化生產設備在節能環保方面也展現出優勢。高效的機械設計減少了能源消耗,而自動化控制系統能精準管理資源,減少浪費。在可持續發展理念下,許多工廠開始采用綠色自動化技術,如使用再生能源驅動的設備,進一步降低碳足跡。
隨著5G、邊緣計算和機器人技術的融合,工廠自動化將邁向更高水平的自主化。人機協作將成為新趨勢,機械科技將助力工廠實現柔性生產,快速響應市場變化。自動化生產設備不僅是機械科技的杰作,更是推動工業4.0的關鍵力量,為全球制造業帶來前所未有的變革。